GPT-5: A Very Brief Post-Mortem

A quick analysis of GPT-5's launch and what it means for you and the future of AI.
GPT-5 was widely heralded as one of the most anticipated model releases of all time. Given that, it’s no surprise that OpenAI seemed rather hesitant to release its new flagship, delaying a speculated early summer launch all the way to August. So, did GPT-5 live up to the hype?
The Launch Event
Well, the launch livestream was certainly something special, with moments like this graph that went viral on the internet:
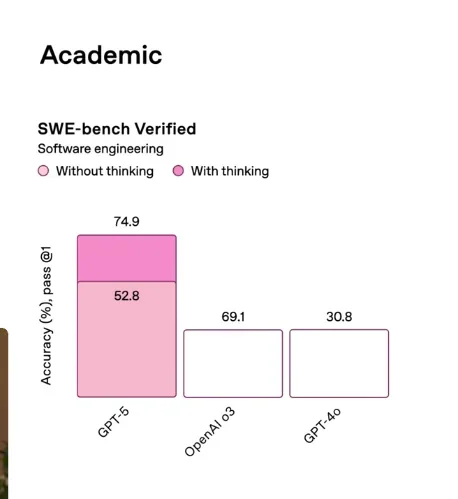
These things really make you wonder what’s going on in OpenAI’s graph generation department. I’ve seen speculations online that this was a marketing gimmick by OpenAI to go viral. These days, it’s hard to figure out what is a stroke of marketing genius by Sam Altman, and what is sheer luck (think of the studio ghibli phenomenon). Ultimately, though, despite the horrific graph crime, GPT-5 is still obviously superior to its predecessor, o3.
Thinking vs. Non-Thinking Models
Well, let’s clarify that a bit: GPT-5 thinking is superior to o3. Now, you might be wondering what that means. According to OpenAI, the newly released models match up with their old counterparts like this:1
| Old Model | → | New GPT-5 Model |
|---|---|---|
| GPT-4o | → | gpt-5-main |
| GPT-4o-mini | → | gpt-5-main-mini |
| OpenAI o3 | → | gpt-5-thinking |
| OpenAI o4-mini | → | gpt-5-thinking-mini |
| GPT-4.1-nano | → | gpt-5-thinking-nano |
| OpenAI o3 Pro | → | gpt-5-thinking-pro |
This is an incredibly important distinction and something that OpenAI did a very poor job of clarifying at launch. There are essentially two completely different models, the main model (which is quite weak, for lack of better phrasing), and the thinking model, which is definitely deserving of the term “frontier model.” This difference is quite important, because Altman & Co. clearly realized that although they wanted to consolidate model branding with GPT-5, it was ultimately impossible to merge the entire ChatGPT product into one singular model. Thus, the solution (something that OpenAI had long denied prior to the launch) was to implement what is known as the model router.
The Model Router
Router Functionality
What is a model router? Essentially, it is a dumb, but extremely fast model that first looks at your query when you send a message to the AI. Then, this model asks itself: is this question worth thinking about (e.g., a difficult math problem), or one that can be answered easily (e.g., “What is the capital of France?”). Then, it directs the question to the actual LLM, either GPT-5 Thinking or GPT-5 non-thinking, to answer it.
This comes with two obvious issues. The first is that the router does not really know best what model to select. For example, a riddle may seem deceptively easy but actually require deep thought. Second, users may want to pick which model to use. To OpenAI’s credit, they have implemented a neat skip button to bypass the slow thinking model.

However, the biggest takeaway from this model router (and the continued presence of the pesky dropdown selector), is that there are still many different variants of GPT-5 to pick from. And this brings us perfectly to perhaps the most important topic related to GPT-5, which is the effect for ChatGPT free users.
Free User Experience
Much discussion before the launch revolved around the reportedly massive increase in capability that free users would be receiving with a jump from GPT-4o, a very weak non-reasoning model, to GPT-5, which presumably would be one of the smartest models in the world. However, it turns out that free users only receive a very limited number of prompts on GPT-5, and are unable to select GPT-5 thinking, instead forced to subject themselves to the pain of the model router.
Thus, the ultimate impact on the free user experience was likely severely overstated, and free users seeking top of the line reasoning models will still have to rely on Google’s Gemini 2.5 Pro via AI Studio. However, the response to the removal of GPT-4o was very interesting, leading to extreme backlash, so look out for an article on that next week! But now, let’s get into the effects for ChatGPT Plus users.
Plus User Quotas
The experience for paid users was certainly a rollercoaster. I think this tweet from @scaling101 sums it up best:
BREAKING: Incredible ChatGPT Plus Limit Updates pic.twitter.com/QINhyPdTGD
— Lisan al Gaib (@scaling01) August 10, 2025
Essentially, reasoning model limits for Plus users were initially cut from 2900 to a measly 200 queries per week. As you might expect, the public backlash to this cut was quite severe, and OpenAI ultimately decided to raise limits back to 3000, exceeding the previous quotas. However, the damage to OpenAI’s image has definitely been done for power users who were outraged by the initial low quotas. Sam Altman himself also replied to this post, calling it “the best meme i have seen in a long time,” so OpenAI is certainly admitting to their mistakes.2
Performance Metrics
If you’re interested in the nitty gritty of the benchmarks, you can refer to the full blog post. I’m not going to get into too much detail, since most of the benchmarks are just marginal improvements over o3.
LMArena Rankings
Well, GPT-5 scored rank 1 on LMArena, a platform where users anonymously rate models based on the quality of their output (look out for an article on the platform in the future):
GPT-5 is here - and it’s #1 across the board.
— lmarena.ai (@arena) August 7, 2025
🥇#1 in Text, WebDev, and Vision Arena
🥇#1 in Hard Prompts, Coding, Math, Creativity, Long Queries, and more
Tested under the codename “summit”, GPT-5 now holds the highest Arena score to date.
Huge congrats to @OpenAI on this… https://t.co/QArg7vguYO pic.twitter.com/NZYIATjNhw
Hallucination Reduction
The benchmarks are certainly also impressive, with the most important being the reduced hallucinations:
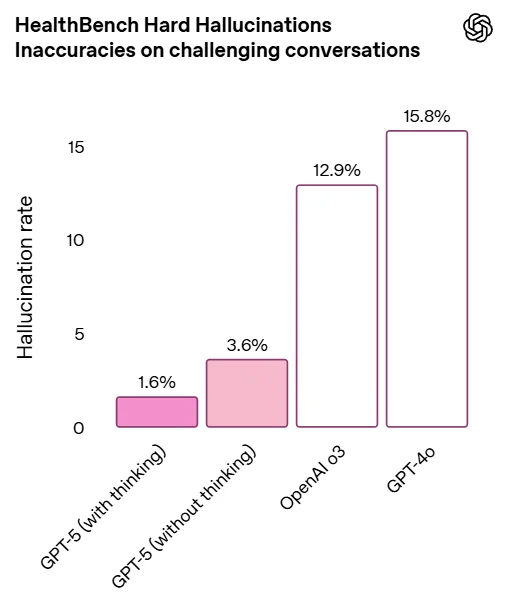
Essentially, this model knows how to say “I don’t know,” which is unbelievably important. In practice, the model has also proven to be very effective, and I have mostly migrated from Gemini 2.5 Pro/Claude Opus 4.1 to GPT-5 Thinking as my primary “chatbot” model.
API Pricing
Surprisingly, the API costs for GPT-5 are actually quite reasonable. If you don’t know what that means, that’s for developers who are using ChatGPT for their own applications and paying per token (which is basically a type of word, but just how the AI reads it rather than humans). If you just use the ChatGPT app/website, you don’t need to worry about it. But for developers, here’s the breakdown:3
| Model | Input | Cached Input | Output | Best For |
|---|---|---|---|---|
| GPT-5 | $1.25 | $0.125 | $10.00 | Coding & agentic tasks |
| GPT-5 mini | $0.25 | $0.025 | $2.00 | Well-defined tasks |
| GPT-5 nano | $0.05 | $0.005 | $0.40 | Summarization & classification |
Prices per 1M tokens
The output pricing may seem pricy for GPT-5 at $10 per million tokens, and it does make those lengthy chain-of-thought responses expensive. But it is quite reasonable compared to other models on the same level. Plus, they have cached input prices if you’re repeatedly hitting the same context.
How to Actually Use GPT-5
Here’s what I’ve learned after using GPT-5 for a while. GPT-5 Thinking is genuinely excellent at math, coding, and complex reasoning tasks. You can paste your entire codebase in and ask questions, and it’ll actually understand what’s going on. It’s also surprisingly agentic, and it searches the internet when it doesn’t know something, so hallucinations are way less of a problem. This is actually huge. You might think that you could simply use Deep Research, or that other models already have this capability. But the way that GPT-5 Thinking uses the internet to supplement the information it doesn’t know is so effective you simply have to try it out.
There is one small catch, though. Prompting GPT-5 Thinking is weirdly particular. It’s been tuned to follow instructions too well, to the point where it can be counterproductive. For serious tasks, I’d recommend using the prompt optimizer – it helps craft prompts that actually work with the model’s quirks.
As for GPT-5 standard (non-thinking), it’s good for questions that a human wouldn’t need to think about. But honestly? If there’s any complexity at all, just use GPT-5 Thinking. Yes, it’s slower, but the standard model fumbles on anything remotely challenging, and the time you’ll waste evaluating the dumber answers is not worth it.
My anecdotal experience: In the past, o3, Gemini 2.5 Pro, and Claude Opus would each get different questions right and wrong and I’d have to try all three sometimes. But GPT-5 Thinking usually gets everything right that the other models do, plus a tiny bit more. I also haven’t seen any egregiously incorrect answers in my own testing on reasonable questions (not inane riddles). It’s definitely worth trying if you’re frustrated with inconsistent results from other models.
Implications for AI Development
At face level, the disastrous launch of GPT-5 serves as perfect ammunition for AI skeptics like Gary Marcus to declare the end of AI acceleration and the ineffectiveness of LLM scaling. However, I think the ultimate story is more nuanced. If we look at the lucky few who had early access to a checkpoint (a version) of GPT-5 Thinking, the reviews were overwhelmingly positive, and it seems that the model actually released is not a true representation of OpenAI’s frontier capabilities. This is understandable given the size of the ChatGPT userbase and the cost of serving reasoning models at high volume, but ultimately means that people like us really have no idea of how fast the frontier is advancing.
So, I’ll say again that you should probably stop worrying about such things and just try the model out. Even though it’s a weaker version than was given to beta testers, GPT-5 Thinking does feel extremely strong as a chatbot.
Footnotes
-
For full technical details on model comparisons and capabilities, see the GPT-5 System Card. ↩
-
Sam Altman’s response acknowledging the quota controversy: https://x.com/sama/status/1954704038068724055 ↩
-
Current API pricing information from OpenAI API Pricing. ↩
Disclaimer
The information in this article is accurate to the author's best knowledge as of August 24, 2025. The views and opinions expressed in this article are those of the author alone and do not necessarily reflect the official policy or position of any organization. This content is provided for informational purposes only and should not be construed as professional advice. While we strive for accuracy, we make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, or suitability of the information contained herein. Any reliance you place on such information is strictly at your own risk.
Comments